Непрерывное тестирование в CI/CD: как наладить процессы QA и ускорить релизы
 мая, 20 2026
мая, 20 2026
Вы когда-нибудь замечали, как быстро меняется код в вашем проекте? Сегодня добавили кнопку, завтра переписали API, послезавтра - новый микросервис. Если при каждом таком изменении команда вручную проверяет всё приложение, вы рискуете утонуть в багах или упустить дедлайн. Именно здесь на сцену выходит непрерывное тестирование, которое обеспечивает автоматическую проверку качества кода на каждом этапе конвейера CI/CD. Это не просто модный термин из мира DevOps, а реальная необходимость для любого проекта, который хочет выпускать обновления быстро и без страха сломать продакшен.
Раньше тестировщики ждали релиза неделями, чтобы найти критические ошибки. Сейчас мы стремимся к тому, чтобы дефекты находились за минуты после коммита. Как это работает на практике? Какие инструменты нужны? И главное - как организовать процессы QA так, чтобы они не тормозили разработчиков, а помогали им? Разберём по шагам.
Что такое непрерывное тестирование и зачем оно нужно
Давайте начнём с основ. Continuous Integration (CI) - это практика, при которой разработчики сливают свои изменения в общий репозиторий несколько раз в день. Каждое такое слияние запускает автоматическую сборку и базовые проверки. А Continuous Delivery (CD) - процесс подготовки этого кода к выпуску в реальную среду.
Непрерывное тестирование - это клей, который держит эти два процесса вместе. Оно означает, что тесты запускаются автоматически на каждом этапе: от проверки синтаксиса кода до нагрузочного тестирования готового приложения. Главная цель - сместить фокус поиска ошибок как можно ближе к моменту написания кода (подход shift-left testing). Почему это важно? Потому что исправить ошибку на этапе разработки стоит в разы дешевле, чем ловить её на сервере заказчика.
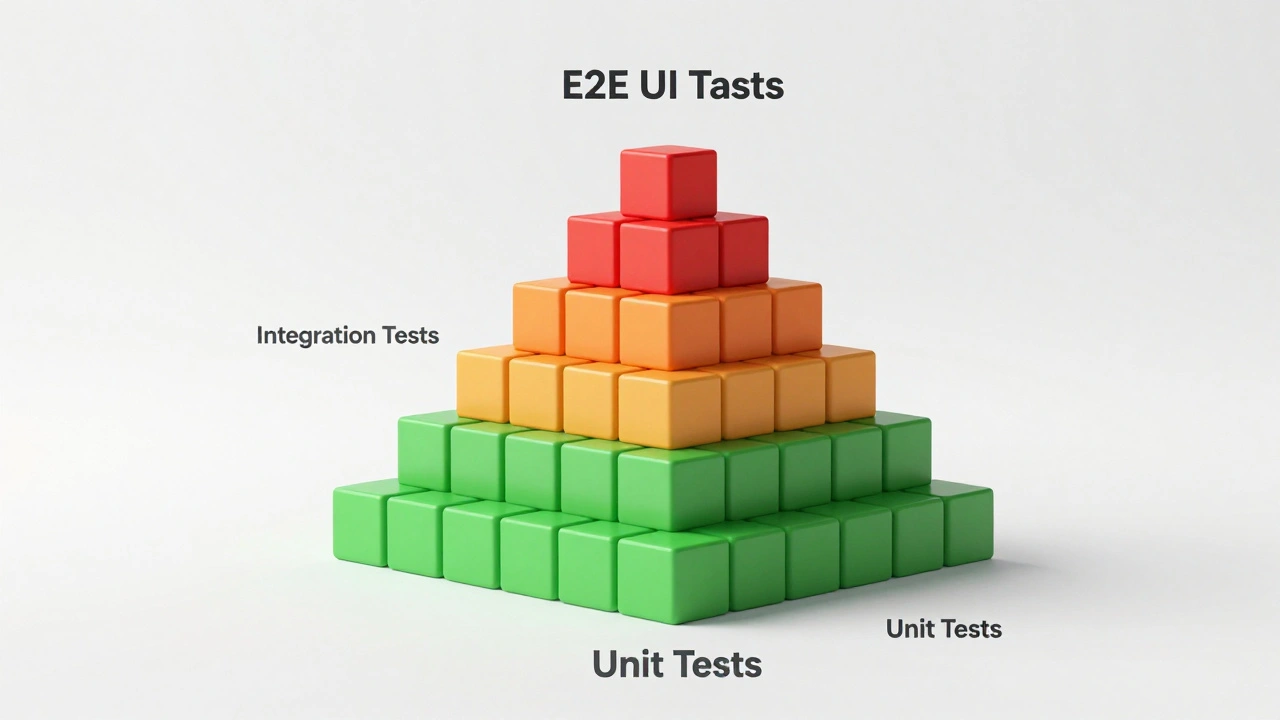
Структура тестовой пирамиды в CI/CD
Чтобы пайплайн не превратился в вечный процесс ожидания, нужно правильно расставить приоритеты тестам. Представьте себе пирамиду:
- Основа (70-80%): Юнит-тесты. Они самые быстрые, дешевые и изолированные. Проверяют отдельные функции или методы. В CI они должны запускаться первыми и завершаться за считанные минуты.
- Средний слой (10-20%): Интеграционные тесты. Проверяют взаимодействие между модулями, базами данных и внешними сервисами. Здесь часто используются контейнеры Docker для эмуляции окружения.
- Вершина (5-10%): E2E/UI-тесты. Самые медленные и дорогие. Они имитируют действия реального пользователя в браузере. Их должно быть минимум, только для самых критичных бизнес-сценариев.
Если ваша пирамида перевернута (много UI-тестов и мало юнит-тестов), ваш CI/CD будет работать медленно, а команда будет нервничать каждый раз при пуше кода.
Этапы пайплайна: какие тесты где запускать
Типичный конвейер выглядит как цепочка этапов. Давайте посмотрим, что происходит на каждом из них:
- Checkout и сборка. Код скачивается, зависимости устанавливаются. Если сборка падает - дальше идти некуда.
- Static Analysis (SAST). Инструменты вроде SonarQube или Semgrep проверяют код на наличие дыр в безопасности, плохих практик и «кошмарных» конструкций. Это занимает 1-5 минут, но спасает от многих проблем.
- Unit-тесты. Запускаются параллельно. Если покрытие ниже установленного порога (например, 60-80%), билд помечается красным.
- Интеграционные тесты. Поднимаются временные базы данных и сервисы. Проверяется корректность обмена данными между компонентами.
- Деплой в тестовое окружение. Приложение собирается в образ (Docker) и разворачивается на стенде Test или Stage.
- Smoke-тесты. Быстрая проверка «живо ли приложение». Открывается главная страница, проверяются health-endpoints. Длится 1-3 минуты.
- E2E и Regression. Полноценная проверка ключевых сценариев. Может занимать от 10 до 30 минут.
Важно понимать: если на любом из ранних этапов тест падает, последующие этапы не запускаются. Это экономит ресурсы серверов и время людей.
Инструменты для организации QA процессов
Без правильного набора инструментов автоматизация останется лишь красивой идеей. Вот список лидеров рынка на 2026 год:
| Категория | Инструменты | Для чего нужен |
|---|---|---|
| CI/CD Серверы | Jenkins, GitLab CI, GitHub Actions, TeamCity | Оркестрация пайплайнов, запуск задач |
| Юнит-тесты | Jest (JS), pytest (Python), JUnit (Java), Go test | Проверка отдельных единиц кода |
| E2E / UI | Cypress, Playwright, Selenium | Имитация действий пользователя в браузере |
| API Тесты | Postman/Newman, REST Assured, Karate | Проверка контрактов и ответов сервера |
| Нагрузочные тесты | k6, JMeter, Gatling | Проверка производительности под нагрузкой |
| Отчетность | Allure Report, ReportPortal | Визуализация результатов тестов |
Обратите внимание на Playwright и Cypress. Они стали стандартом де-факто для UI-тестирования благодаря скорости и стабильности, превосходящей старый добрый Selenium во многих сценариях. Для API-тестов активно используют Karate, который позволяет писать тесты на понятном языке Gherkin.
Роли и ответственность в команде
Непрерывное тестирование - это не только задача QA-инженеров. Это командный вид спорта.
- Разработчики пишут юнит-тесты и обеспечивают базовое покрытие. Они отвечают за то, чтобы их код не ломал существующую функциональность.
- SDET (Software Development Engineer in Test) строят архитектуру автотестов, выбирают фреймворки и интегрируют их в CI/CD. Они пишут сложные интеграционные и E2E тесты.
- DevOps-инженеры настраивают сами пайплайны, управляют инфраструктурой (Kubernetes, Docker) и обеспечивают доступность тестовых сред.
- Product Owner определяет критерии приемки (Definition of Done). Например: «Код считается готовым, если все smoke-тесты зеленые, а coverage выше 70%».
Когда роли четкие, исчезает вопрос «кто виноват», если тест упал. Вместо этого команда сразу начинает искать решение.

Метрики эффективности: как понять, что всё работает
Без цифр нельзя управлять качеством. Вот ключевые метрики, которые стоит отслеживать:
- Build Success Rate: Доля успешных сборок. Если она ниже 70-80%, значит, система нестабильна или тесты слишком чувствительны («флейковые»).
- Lead Time for Changes: Время от коммита до деплоя в прод. Цель - сократить его до часов, а не дней.
- Change Fail Rate: Процент релизов, которые пришлось откатывать. У зрелых команд он стремится к нулю.
- Flaky Tests Ratio: Доля тестов, которые падают случайно. Это зло №1 в CI/CD. Такие тесты подрывают доверие к системе и должны либо фиксироваться, либо удаляться.
- Time to Feedback: Как быстро разработчик узнает об ошибке. Идеально - в течение 10-15 минут после пуша.
Типичные проблемы и как их избежать
В процессе внедрения вы неизбежно столкнетесь с трудностями. Вот самые частые:
«Флейковые» тесты. Тест то проходит, то падает без видимых причин. Причина часто кроется в зависимостях от времени, сети или состояния базы данных. Решение: изолировать тесты, использовать моки, добавить явные ожидания (explicit waits) вместо пауз.
Слишком долгий пайплайн. Если полный регресс идет час, никто не захочет ждать. Решение: параллелизация тестов на разных агентах, запуск только тех тестов, которые затронул измененный код (test impact analysis).
Дублирование тестов. Один и тот же сценарий проверен и на уровне UI, и на уровне API, и интеграционно. Это удваивает время выполнения. Решение: оставить один самый надежный уровень проверки для каждого кейса.
Проблемы с тестовыми данными. Данные «грязнятся» после предыдущего прогона. Решение: использовать транзакции (откат после теста) или генерировать уникальные данные динамически.
Пошаговый план внедрения
Не пытайтесь сделать всё сразу. Внедряйте непрерывное тестирование постепенно:
- Начните с базового CI. Настройте сборку и линтинг. Пусть каждый пуш проверяет синтаксис.
- Добавьте юнит-тесты. Введите обязательный порог покрытия. Сделайте так, чтобы билд падал при низком качестве кода.
- Автоматизируйте деплой в тестовую среду. После успешного CI код должен сам попадать на стенд.
- Внедрите Smoke-тесты. Проверьте, что приложение запустилось и основные страницы открываются.
- Добавьте E2E-тесты для критичных путей. Регистрация, оплата, поиск. Не тестируйте всё подряд, только самое важное.
- Интегрируйте безопасность и нагрузку. SAST-сканирование и простые чекеры производительности.
Каждый шаг должен приносить ценность. Не стройте сложную систему ради системы. Главное - получить быструю обратную связь о качестве продукта.
Чем отличается Continuous Testing от обычного автоматического тестирования?
Обычное автоматическое тестирование может выполняться раз в неделю перед релизом. Непрерывное тестирование интегрировано в CI/CD и запускается при каждом изменении кода. Это обеспечивает мгновенную обратную связь и позволяет находить дефекты на самой ранней стадии, снижая стоимость их исправления.
Как бороться с «флейковыми» тестами в CI/CD?
Сначала идентифицируйте такие тесты по логам. Часто причина в жестких таймаутах или зависимости от внешних ресурсов. Используйте явные ожидания (explicit waits) вместо sleep(), мокируйте внешние сервисы и убедитесь, что тесты независимы друг от друга. Флейковые тесты следует временно исключать из пайплайна, пока они не будут исправлены.
Какие инструменты лучше выбрать для старта?
Для начала достаточно связки: GitLab CI или Jenkins для оркестрации, Jest/pytest/JUnit для юнит-тестов и Cypress или Playwright для E2E. Эти инструменты имеют хорошую документацию, большие сообщества и легко интегрируются друг с другом. Не усложняйте стек на старте.
Стоит ли запускать все тесты при каждом коммите?
Нет, это приведет к длительному ожиданию. При каждом коммите запускайте только быстрые проверки: линтинг, юнит-тесты и базовые интеграционные тесты. Полный регрессионный набор и тяжелые E2E-тесты стоит запускать реже, например, ночью или перед созданием релизной ветки.
Как измерить эффективность внедрения непрерывного тестирования?
Следите за метриками DORA: частота деплоев, время от коммита до продакшена (Lead Time), процент неудачных релизов (Change Fail Rate) и время восстановления после сбоя (MTTR). Также важно мониторить скорость прохождения пайплайна и долю успешных билдов.