Мониторинг приложений: настройка Prometheus и Grafana для DevOps
 мая, 1 2026
мая, 1 2026
Представьте ситуацию: ваш сервер работает, приложение отвечает на запросы, но пользователи жалуются на медленную загрузку страниц. Без правильной системы наблюдения вы будете искать причину вслепую. Именно здесь на сцену выходят Prometheus - система мониторинга и алертинга, основанная на временных рядах, которая собирает метрики по принципу pull-модели. Она стала стандартом де-факто в мире DevOps благодаря своей надежности и мощному языку запросов PromQL. В паре с ней работает Grafana - платформа для аналитики и визуализации данных, позволяющая создавать интерактивные дашборды из различных источников данных. Вместе они образуют связку, которую используют миллионы разработчиков по всему миру, чтобы держать инфраструктуру под контролем и реагировать на сбои до того, как о них узнают клиенты.
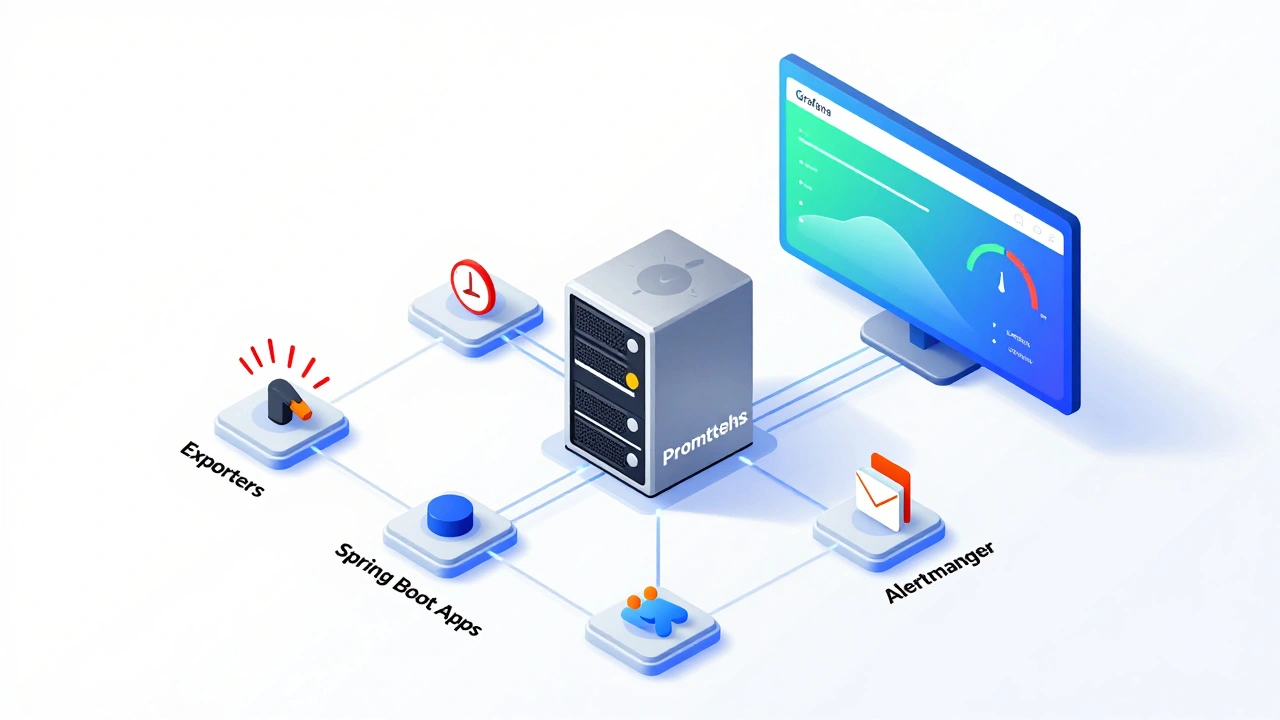
Как устроена архитектура мониторинга
Чтобы система работала эффективно, нужно понимать роль каждого компонента. Архитектура строится на четком разделении обязанностей:
- Экспортеры (Exporters): это специальные программы или встроенные модули приложений, которые собирают сырые данные о работе системы (загрузка CPU, память, количество запросов) и делают их доступными через HTTP-конечную точку
/metrics. - Prometheus Server: центральный узел, который регулярно «опрашивает» (scrape) эти конечные точки. По умолчанию он делает это каждые 15 секунд, хотя этот интервал можно настроить. Собранная информация сохраняется во внутреннем хранилище временных рядов.
- Grafana: не хранит данные сама, а подключается к Prometheus (или другим источникам) через API, чтобы отобразить графики, таблицы и диаграммы.
- Alertmanager: компонент, отвечающий за отправку уведомлений при возникновении критических ситуаций. Он обрабатывает сигналы от Prometheus и рассылает оповещения в Slack, Email или PagerDuty.
Такая структура обеспечивает масштабируемость. Вы можете добавлять новые источники метрик, просто указав их в конфигурации Prometheus, без изменения логики самого приложения.
Сбор метрик от приложений Spring Boot
Одним из самых популярных сценариев использования является мониторинг микросервисов на базе Java. Если вы используете Spring Boot - фреймворк для создания корпоративных Java-приложений, предоставляющий инструменты для быстрого старта и развертывания, интеграция с Prometheus происходит практически автоматически.
Для этого используются два ключевых инструмента:
- Spring Boot Actuator: предоставляет конечные точки для управления приложением и получения информации о его состоянии.
- Micrometer: библиотека фасадного уровня, которая абстрагирует процесс сбора метрик. Она форматирует данные так, чтобы Prometheus мог легко их прочитать.
После добавления необходимых зависимостей в проект, метрики становятся доступны по адресу http://localhost:8080/actuator/prometheus. Здесь вы увидите технические показатели, такие как среднее время отклика HTTP-запросов, количество ошибок, использование потоков и памяти JVM. Также можно отслеживать бизнес-метрики: количество оформленных заказов, средний чек или конверсию воронки продаж.
Настройка конфигурации Prometheus
Сердце настройки Prometheus - файл prometheus.yml. В нем задаются глобальные параметры и список целей для сбора данных. Типичная конфигурация выглядит следующим образом:
global:
scrape_interval: 15s # Как часто собирать метрики
evaluation_interval: 30s # Как часто проверять правила алертов
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node_exporter'
static_configs:
- targets: ['localhost:9100']
- job_name: 'spring_app'
metrics_path: '/actuator/prometheus'
static_configs:
- targets: ['my-app-server:8080']Параметр scrape_timeout обычно устанавливается на 10 секунд, чтобы избежать блокировки потока сбора данных, если целевой сервис отвечает медленно. Правильная настройка этих таймаутов критически важна для стабильности всей системы мониторинга.
Визуализация данных в Grafana
Собранные данные бесполезны, если их нельзя понять. Grafana позволяет создавать дашборды, которые адаптируются под ваши задачи. Вы можете использовать готовые панели из сообщества или создать свои собственные.
Основные типы визуализаций включают:
- Графики (Time Series): показывают изменение метрик во времени, например, рост нагрузки на CPU.
- Калькуляторы (Stat): отображают текущее значение важной метрики, такой как количество активных пользователей.
- Диаграммы (Gauge): полезны для отображения прогресса заполнения диска или памяти.
Интересная функция Grafana - режим TV. Он позволяет вывести дашборд на большой экран в центре управления сетью (NOC), где команда может в реальном времени наблюдать за пульсацией инфраструктуры. Это особенно полезно во время масштабных релизов или технических работ.
| Характеристика | Prometheus | Grafana |
|---|---|---|
| Основная функция | Сбор и хранение метрик | Визуализация и анализ |
| Модель сбора | Pull (опрос) | N/A (подключение к источникам) |
| Язык запросов | PromQL | Зависит от источника (PromQL, SQL, etc.) |
| Алертинг | Генерация правил | Управление уведомлениями (через Alertmanager) |
Алертинг и оперативное реагирование
Мониторинг бесполезен, если вы видите проблему только после того, как она произошла. Система алертинга должна предупреждать вас заранее. В Prometheus правила алертинга определяются в отдельных файлах YAML. Например, вы можете настроить правило, которое сработает, если процент ошибок HTTP 500 превысит 5% в течение 5 минут.
Когда условие выполняется, Prometheus отправляет сигнал в Alertmanager - компонент системы мониторинга Prometheus, отвечающий за агрегацию, группировку и маршрутизацию алертов. Alertmanager умеет дедуплицировать уведомления, группировать похожие инциденты и отправлять их нужным каналам связи. Это предотвращает «алертный шум», когда команда получает сотни сообщений об одной и той же проблеме.
Преимущества связки Prometheus и Grafana
Почему именно эта пара стала лидером рынка? Во-первых, открытость. Оба инструмента имеют открытый исходный код и поддерживаются активным сообществом. Во-вторых, гибкость. Prometheus может собирать метрики не только от серверов, но и от сетевого оборудования, IoT-устройств и даже скриптов на Raspberry Pi, если они предоставляют данные в формате OpenMetrics.
В-третьих, интеграция с облачными технологиями. Prometheus отлично работает с Kubernetes, автоматически обнаруживая новые поды и сервисы. Это делает его идеальным выбором для современных микросервисных архитектур. Grafana, в свою очередь, поддерживает десятки источников данных, включая Elasticsearch, InfluxDB и CloudWatch, что позволяет объединять разрозненные данные в единую картину.
Как часто Prometheus собирает метрики?
По умолчанию интервал сбора (scrape_interval) составляет 15 секунд. Однако вы можете изменить это значение в конфигурационном файле prometheus.yml в зависимости от требуемой детализации данных и нагрузки на систему.
Нужно ли устанавливать базу данных для Prometheus?
Нет, Prometheus имеет собственное встроенное хранилище временных рядов (TSDB). Данные сохраняются локально на диске сервера Prometheus. Для долгосрочного хранения можно использовать удаленные write-адаптеры, такие как Thanos или Cortex.
Можно ли использовать Grafana без Prometheus?
Да, Grafana является независимым инструментом визуализации. Она поддерживает множество источников данных, включая PostgreSQL, MySQL, InfluxDB, Elasticsearch и другие. Prometheus - лишь один из многих возможных источников.
Как добавить метрики в Spring Boot приложение?
Необходимо добавить зависимости spring-boot-starter-actuator и micrometer-registry-prometheus в проект. После этого метрики станут доступны по endpoint /actuator/prometheus в формате, понятном Prometheus.
Что такое Pull-модель сбора данных?
В Pull-модели сервер мониторинга (Prometheus) активно запрашивает данные у целевых сервисов по расписанию. Это отличается от Push-модели, где сервисы сами отправляют данные на сервер. Pull-модель проще в управлении, так как сервер контролирует процесс сбора и может легко обнаружить недоступные цели.