Hadoop: как работает распределенная обработка больших данных в кластере
 мая, 29 2026
мая, 29 2026
Представьте себе библиотеку, где книг так много, что они не помещаются ни на одной полке. Вы не можете прочитать их все сразу, стоя у одного стола. Вам нужно разбить эту задачу: одни люди переносят книги, другие читают главы, третьи делают конспекты, а четвертые сводят итоги. Именно так работает Apache Hadoop, который является открытым программным фреймворком для надежных и масштабируемых распределенных вычислений и хранения больших данных на кластерах из сотен и тысяч узлов. Он позволяет обрабатывать петабайты информации, используя обычные компьютеры, соединенные в сеть.
Многие до сих пор думают, что Hadoop - это просто база данных или устаревшая технология. Это не так. Hadoop - это фундамент, на котором строится современная аналитика. Даже если сегодня компании переходят в облака, принципы, заложенные в Hadoop (распределенное хранение и вычисления), остаются актуальными. В этой статье мы разберем, как именно этот механизм работает внутри, почему он до сих пор используется банками и телеком-операторами, и с чем его сравнивают инженеры в 2026 году.
Архитектура Hadoop: четыре столпа системы
Чтобы понять, как Hadoop справляется с огромными объемами данных, нужно заглянуть под капот. Система состоит из четырех основных компонентов, каждый из которых выполняет свою роль. Без одного из них весь механизм перестанет работать эффективно.
- Hadoop Common: Это набор библиотек и утилит на Java, которые используются всеми остальными компонентами. Здесь живут инструменты для сериализации данных, удаленного вызова процедур (RPC) и настройки конфигурации. Можно сказать, что это «клей», держащий систему вместе.
- HDFS (Hadoop Distributed File System): Распределенная файловая система. Она хранит сами данные. Файлы разбиваются на блоки (по умолчанию 128 или 256 МБ) и распределяются по разным серверам (DataNode). Каждый блок копируется три раза на разные узлы для надежности. Если один сервер сломается, данные останутся доступными с других копий.
- YARN (Yet Another Resource Negotiator): Менеджер ресурсов. Появившийся в версии Hadoop 2.0, он отделяет управление ресурсами от вычислений. YARN решает, какой процессор и память выделить конкретной задаче. Благодаря ему на одном кластере можно запускать не только MapReduce, но и Apache Spark, Flink или Tez.
- MapReduce: Модель программирования для обработки данных. Она делит задачу на две части: Map (разделение и преобразование данных в пары «ключ-значение») и Reduce (агрегация результатов). Это классический подход для пакетной обработки.
Важно понимать, что NameNode (сервер метаданных в HDFS) хранит информацию о том, где лежат файлы, в оперативной памяти. Поэтому Hadoop плохо работает с миллионами мелких файлов - это перегружает память NameNode. Система оптимизирована для работы с большими файлами (десятки гигабайт и более).
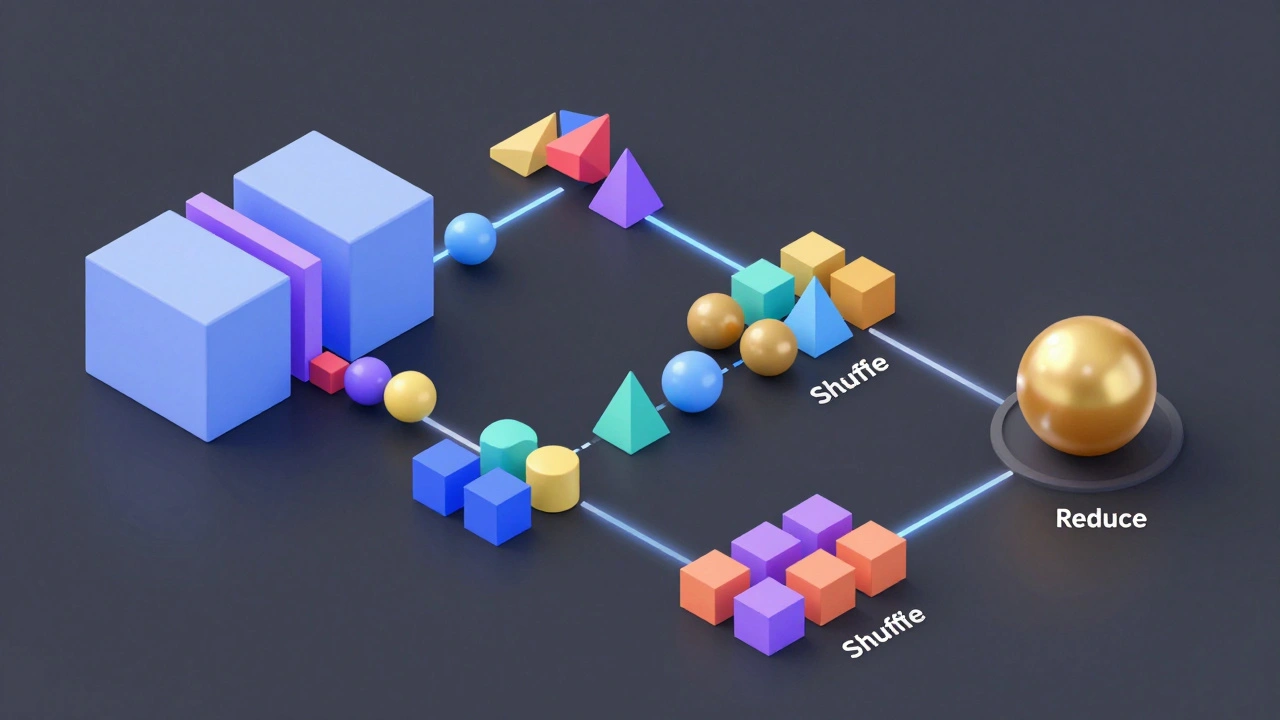
Как происходит обработка данных: пример MapReduce
Давайте посмотрим, как выглядит работа системы на практике. Представьте, что вам нужно посчитать количество слов во всех книгах мировой литературы, хранимых в кластере.
| Этап | Действие | Пример в контексте подсчета слов |
|---|---|---|
| Input Splitting | Разбиение входных данных на чанки | Книги разбиваются на блоки по 128 МБ |
| Map Phase | Обработка каждого блока независимо | Каждый узел читает свой блок и выдает пары: («слово», 1) |
| Shuffle Phase | Группировка данных по ключам | Все упоминания слова «кот» собираются вместе |
| Reduce Phase | Агрегация итоговых значений | Суммирование единиц для каждого уникального слова |
| Output | Запись результата в HDFS | Файл со списком слов и их частотой |
Главное преимущество этого подхода - горизонтальное масштабирование. Если данных стало в 10 раз больше, вы просто добавляете 10 новых серверов в кластер. Скорость обработки растет пропорционально количеству узлов. В 2009 году кластер Yahoo сортировал 1 ТБ данных за 62 секунды на 910 узлах. Сегодня такие задачи решаются еще быстрее благодаря улучшенному сетевому оборудованию и алгоритмам.
Производительность и системные требования
Запуск Hadoop требует серьезной подготовки инфраструктуры. Это не сервис, который можно установить на домашний ноутбук и забыть. Для тестового кластера достаточно 4-8 ГБ RAM и 2-4 ядер CPU на узел. Но для производственной среды рекомендации совсем другие:
- DataNode (узлы хранения): 64-256 ГБ RAM, 12-32 ядра CPU.
- Дисковое пространство: От 4 до 12 ТБ на узел, желательно использовать JBOD (Just a Bunch of Disks) без аппаратного RAID, так как HDFS сам обеспечивает избыточность через репликацию.
- Сеть: Пропускная способность 1-10 Гбит/с между узлами критически важна для этапа Shuffle.
Один из главных врагов производительности в Hadoop - маленькие файлы. Поскольку метаданные хранятся в памяти NameNode, миллионы файлов размером в килобайты могут «задушить» систему. Инженеры часто объединяют мелкие файлы в архивы или используют форматы колонночного хранения, такие как Parquet или ORC, чтобы снизить нагрузку.
Hadoop против альтернатив: Spark, Flink и облака
В 2026 году вопрос «Hadoop или что-то другое?» звучит иначе, чем десять лет назад. Чистые on-premise кластеры Hadoop становятся реже, но экосистема жива. Давайте сравним Hadoop MapReduce с его главным конкурентом - Apache Spark.
| Характеристика | Hadoop MapReduce | Apache Spark |
|---|---|---|
| Тип обработки | Пакетная (Batch) | Пакетная и потоковая (Streaming) |
| Хранение промежуточных данных | На диск (медленно) | В памяти (RAM) (быстро) |
| Скорость | Низкая для итеративных задач | До 100 раз быстрее MapReduce |
| Сложность кода | Высокая (Java API) | Ниже (поддержка Python, Scala, SQL) |
| Роль в современной архитектуре | Хранение (HDFS) и оркестрация (YARN) | Основной вычислительный движок |
Spark часто запускается поверх Hadoop, используя YARN для управления ресурсами и HDFS для хранения. Таким образом, они не всегда являются взаимозаменяемыми. Hadoop предоставляет инфраструктуру, а Spark берет на себя тяжелую вычислительную работу. Также стоит упомянуть Apache Flink, который лучше подходит для реального времени (real-time analytics), и облачные решения вроде Amazon EMR или Google Dataproc, которые убирают необходимость администрировать железо самостоятельно.

Безопасность и стоимость владения
Сама платформа Apache Hadoop бесплатна (лицензия Apache 2.0). Однако стоимость владения складывается из зарплаты специалистов, электричества и оборудования. Коммерческие дистрибутивы, такие как Cloudera или бывшие продукты Hortonworks, предлагают поддержку и дополнительные модули безопасности. Цена подписки может составлять от 2000 до 5000 долларов США за узел в год.
По умолчанию Hadoop не настроен на максимальную безопасность. Для защиты данных в корпоративном секторе обычно внедряют:
- Kerberos: Для аутентификации пользователей и служб.
- Apache Ranger: Для управления правами доступа (ACL).
- Шифрование: TLS/SSL для передачи данных и Transparent Data Encryption для хранения на дисках.
Настройка этих компонентов требует высокой квалификации DevOps-инженеров. Ошибка в конфигурации Kerberos может парализовать работу всего кластера на дни.
Где применяется Hadoop сегодня?
Несмотря на рост облачных технологий, Hadoop остается рабочим инструментом в отраслях, где данные чувствительны к суверенитету или объему:
- Банковский сектор: Анализ транзакций, кредитный скоринг на базе десятков терабайт истории операций.
- Телекоммуникации: Обработка CDR-логов (записей звонков) для анализа качества сети и выявления мошенничества.
- Retail: Персонализация рекомендаций и анализ корзины покупателя на основе исторических данных продаж.
- Госсектор: Хранение больших архивов документов и журналов событий.
В России многие крупные компании продолжают поддерживать свои локальные кластеры, адаптируя их под требования импортозамещения. При этом наблюдается миграция части нагрузок в управляемые облачные решения от местных провайдеров, таких как Selectel или Yandex Cloud, которые предлагают managed-Hadoop сервисы.
Умер ли Hadoop?
Нет, Hadoop не умер, но трансформировался. Классический MapReduce уходит на второй план, уступая место Spark и Flink. Однако HDFS (хранение) и YARN (управление ресурсами) остаются основой многих Big Data платформ. Кроме того, принципы Hadoop легли в основу современных lakehouse-архитектур.
Для чего нужен YARN в Hadoop?
YARN (Yet Another Resource Negotiator) отвечает за управление ресурсами кластера (CPU, RAM). До появления YARN в Hadoop 2.0 можно было запускать только MapReduce. Теперь YARN позволяет одновременно работать разным движкам: Spark, Hive, Presto, распределяя между ними ресурсы серверов.
Почему Hadoop плохо работает с маленькими файлами?
Потому что метаданные обо всех файлах хранятся в оперативной памяти NameNode. Миллионы маленьких файлов создают огромную нагрузку на память, ограничивая масштабируемость системы. Для таких случаев рекомендуют использовать архивацию или форматы типа HBase.
Какая версия Hadoop актуальна в 2026 году?
Актуальной стабильной версией является ветка 3.x (например, Hadoop 3.4.0, выпущенный в апреле 2024 года). Она поддерживает улучшенное кодирование стиранием (Erasure Coding), федерацию NameNode и интеграцию с контейнерными технологиями.
Стоит ли изучать Hadoop начинающему специалисту?
Изучать базовые принципы (HDFS, распределенные вычисления) обязательно, так как это фундамент Big Data. Однако углубляться в написание MapReduce-джобов на Java сейчас менее целесообразно, чем изучение Apache Spark и SQL-подобных языков запросов (Hive SQL, Spark SQL).